

 资讯
资讯

对(duì)联传统(tǒng)源远流长,一幅写春(chūn)联的需要(yào)极高的文学素养,不仅要求平仄齐整、意境对称,还要表达辟邪(xié)除灾、迎祥纳福的(de)美(měi)好愿望。但是对于现代(dài)人来说,由于对传统文学的生疏和(hé)缺(quē)乏对对联的练习,对(duì)对联变得不容易(yì)了。
但是人(rén)工(gōng)智能技术(shù)普及的今天(tiān),攻克对联难关早就有人来尝试进行了。其中(zhōng)最为著(zhe)名,最(zuì)富有文(wén)学气息(xī)的当属微软亚洲研究院的对联系(xì)统,其由微软亚洲研(yán)究院副院长周明负(fù)责开发(fā),并能够利(lì)用本交(jiāo)互方(fāng)式可以(yǐ)随意修改下联(lián)和横批。如下图所示,就“千江有水千江月”一对就可对出“万里无云万里天”。

不过,在新(xīn)奇以及个性化方面不(bú)如最近新崛起的百度春联系统(tǒng),百度开发的对联系统有刷脸出对联以及藏头对联等系统。如(rú)下图所示,以人工智(zhì)能为题眼,AI给(gěi)出的一幅对联(lián)。

不仅能刷脸生成(chéng)对联,还可以预测合成你18岁(suì)时的(de)模(mó)样(yàng)。用一张现有照片试一(yī)下,可以在下方滚动区域清晰的看到(dào)每(měi)一步的文字(zì)。结果显示预(yù)测年龄为30岁,AI给颜值打80分。另外,生成的18岁的照片非常年轻(* ̄︶ ̄)。
当然,还有去(qù)年(nián)非常火的个人版AI对(duì)联,设计者是本科毕业于(yú)黑(hēi)龙(lóng)江大学(xué)计算机专业(yè),硕(shuò)士(shì)毕业于英国莱(lái)斯(sī)特大(dà)学读(dú)计(jì)算机硕士的王斌。从测(cè)试(shì)结果(如下图)来看,对于一般的对联效果也是(shì)杠杠滴~
这个AI的训练,是(shì)基(jī)于深度学习seq2seq模型,用到了TensorFlow和Python 3.6,代码已(yǐ)经(jīng)开(kāi)源,你可以自行打开下面的GitHub地址下载开(kāi)源代码尝试训练。另外,训练它所用的数据集来自一位名为(wéi)冯重(chóng)朴_梨(lí)味斋散叶的博主的新浪博客(kè),总共包含超过(guò)70万副对(duì)联。
所以想自己写春联的,但又憋不出大招的小伙伴,可以使用上述任一(yī)AI系统(tǒng)打造出(chū)属(shǔ)于你(nǐ)自己的对联。
AI对(duì)联(lián)背后(hòu)的技术
关于AI对联(lián)所(suǒ)采用的技术,微软(ruǎn)周明在博(bó)客(kè)中曾经写过这(zhè)样一段话:“我设计了(le)一个(gè)简单的(de)模型,把对联的(de)生成过程(chéng)看作是一个翻译的过程。给定一个上联,根据字的对应和词的对应,生成很多选字和候选词,得(dé)到一(yī)个从左(zuǒ)到(dào)右相互关(guān)联的词图,然后根据(jù)一个动态(tài)规划算法,求一个(gè)最好(hǎo)的(de)下联出来(lái)。
从上述文字我们可(kě)以知道,AI对联采(cǎi)用的是一系列(liè)机器翻译算法(fǎ)。和不(bú)同语言之间(jiān)的翻译(yì)不同的是,给(gěi)出上联,AI对出下联是(shì)同种(zhǒng)语言(yán)之间(jiān)的翻译。
这也就是说对联系统的(de)水平直接依赖(lài)于机器翻译系统的(de)发展历程。
机器翻译的最初(chū)的源头可以追溯到1949年(nián),那(nà)时的技术主流都是基于规则(zé)的(de)机器翻译, 最(zuì)常(cháng)见的做法就是(shì)直接(jiē)根据词典逐字翻(fān)译,但是这种翻译(yì)方法效果确实不太(tài)好。“规则派(pài)”败北之后,日本(běn)京都大学的长尾真(zhēn)教授提出了(le)基于(yú)实例的机器(qì)翻(fān)译,即只要存上足够多的例句,即使遇到不(bú)完全匹(pǐ)配的(de)句子,也可以比对例句,只要替换不一(yī)样的词的翻译(yì)就可以(yǐ)。但这(zhè)种方式并没有掀起多(duō)大的风浪。
1993年发布的《机器翻译的数学(xué)理论(lùn)》论文中提出了由五(wǔ)种以(yǐ)词为单位(wèi)的统计(jì)模型(xíng),其思(sī)路主(zhǔ)要是把翻译当成机率问(wèn)题,这种翻译(yì)方式虽(suī)然在当时风靡一时,但真正掀(xiān)起革命(mìng)的还是2014年深度(dù)学习的兴起。
2016年谷(gǔ)歌(gē)正式宣布将所有统计机器翻译下架(jià),神经网络机器(qì)翻译上位,成为现代机器翻(fān)译的绝对主(zhǔ)流。具(jù)体来说,目前市面上的AI对联(lián)基本上都是基于attention机(jī)制的(de)seq2seq模(mó)型的序列生成任务训练(liàn)而成。seq2seq模型又叫Encoder-Decoder。
关于(yú)此模型AI科(kē)技评(píng)论之前曾经写(xiě)过一篇文章详细介绍,尚未理解的(de)读者请戳此(cǐ)《完全图解RNN、RNN变(biàn)体、Seq2Seq、Attention机制》阅(yuè)读。
现在(zài)我们也把关键部分摘要如下:Encoder-Decoder结(jié)构先将输(shū)入(rù)数据编码(mǎ)成一个上下文向(xiàng)量c:
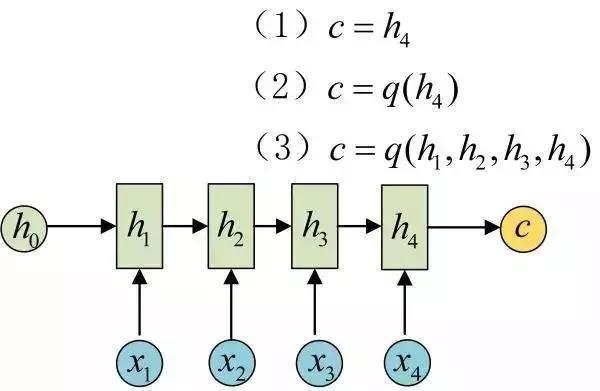
得(dé)到c有多种方式(shì),最简单的方法(fǎ)就是把(bǎ)Encoder的最后(hòu)一个隐状态赋值给c,还可(kě)以对最后的隐状(zhuàng)态(tài)做一(yī)个变换得到c,也可以对(duì)所有的隐状态做变换。
拿(ná)到c之后,就用另一个网络(luò)对(duì)其进(jìn)行解码(mǎ),这部分(fèn)网络结构(gòu)被称(chēng)为Decoder。具体做法(fǎ)就是将c当做之前的初始状(zhuàng)态h0输(shū)入到(dào)Decoder中:
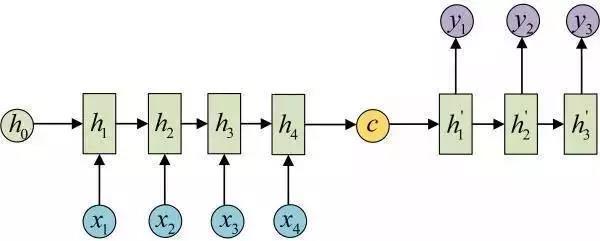
还有一种做法是将c当做每一步的输入:

由于这种(zhǒng)Encoder-Decoder结构(gòu)不限制输入和输出的序列长度,因(yīn)此应用的范(fàn)围非常广泛。
Attention机制
在Encoder-Decoder结构中,Encoder把所(suǒ)有的输入序(xù)列都编码成一个统一的语(yǔ)义特征c再解码,因此,c中必须包含原始序列中(zhōng)的所有(yǒu)信息,它(tā)的长(zhǎng)度就成了限制模型(xíng)性能(néng)的瓶颈(jǐng)。如机器翻译问题,当(dāng)要(yào)翻译的句(jù)子(zǐ)较长时,一(yī)个c可能(néng)存不下那(nà)么多信息,就会造成翻译(yì)精(jīng)度的下降(jiàng)。
Attention机制(zhì)通过在(zài)每个时间输入不同(tóng)的(de)c来(lái)解决这个问题(tí),下图是带有Attention机制的Decoder:

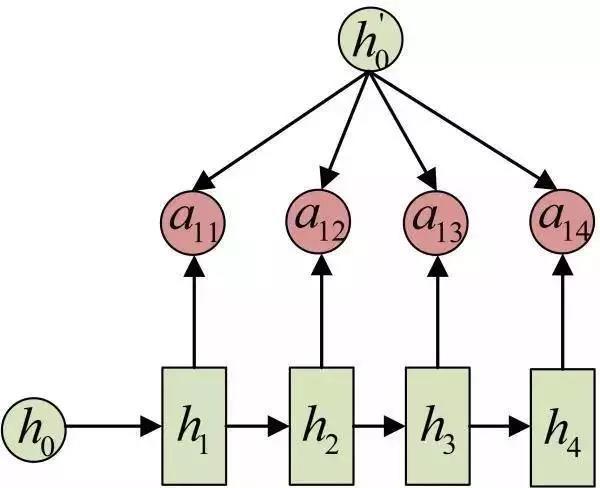
每一个c会自动去选取与当前所要输出的y最合适的上下文信(xìn)息。具(jù)体来说,我们用aij衡量Encoder中第j阶段的hj和解码(mǎ)时第i阶段(duàn)的相关性,最终Decoder中第i阶(jiē)段的(de)输入的上下文(wén)信息 ci就来自于所有 hj 对 aij 的加(jiā)权和。以机器翻译为例(lì)(将(jiāng)中(zhōng)文翻译成(chéng)英文(wén)):
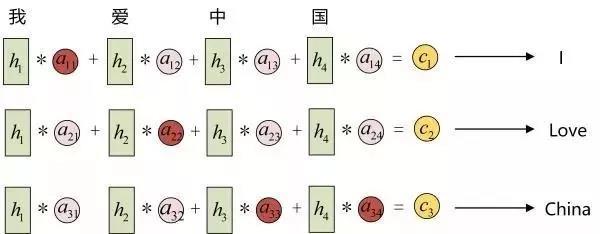
输入的序列是“我爱中国”,因此,Encoder中的h1、h2、h3、h4就可以分别看做是“我”、“爱”、“中”、“国”所代表的信息。在(zài)翻译(yì)成(chéng)英语(yǔ)时,第一个(gè)上(shàng)下文c1应该和(hé)“我(wǒ)”这个字最相(xiàng)关,因此对(duì)应(yīng)的a11就比较大(dà),而相(xiàng)应(yīng)的 a12、a13、a14就比较(jiào)小。c2应(yīng)该和(hé)“爱(ài)”最相关,因此对应(yīng)的a22就比较大(dà)。最后的c3和(hé)h3、h4最相关,因(yīn)此a33、a34的(de)值就(jiù)比(bǐ)较大。
至此,关于Attention模型,我(wǒ)们就只剩最后(hòu)一(yī)个(gè)问题了,那就是(shì):这些权(quán)重aij是怎么来的?
事实上,aij同(tóng)样是从模型中学出的,它实际和Decoder的第i-1阶段(duàn)的隐状态、Encoder第(dì)j个阶段(duàn)的隐状态(tài)有(yǒu)关。
同样还是拿上面的机器翻译举例,a1j的计算(此时箭头就表示对h'和 hj 同时做(zuò)变换):
a2j 的计算:

a3j的计算:
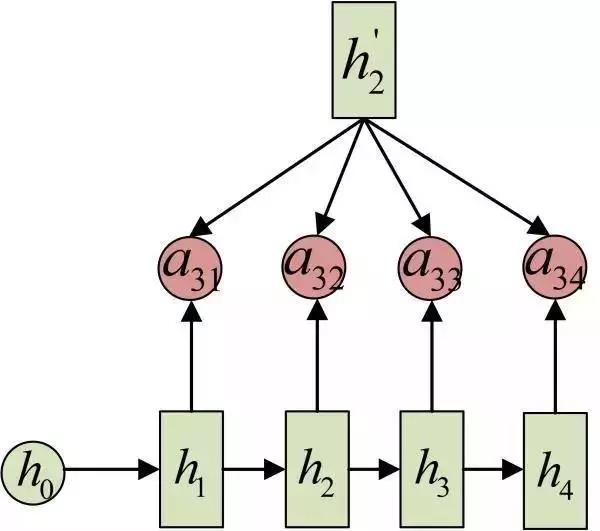
以上就是带有Attention的Encoder-Decoder模型计算的全(quán)过程。
关于解码(mǎ)器(qì)和编码(mǎ)器
解码器和(hé)编码器所用的网络结(jié)构(gòu),在深(shēn)度学习时代大多(duō)使(shǐ)用卷积网络(luò)(CNN)和循环网络(RNN),然而Google 提出了一种新的架构 Transformer也可以作为解码器和编码器。
注:Transformer最初由(yóu)论文《Attention is All You Need》提(tí)出,渐渐有取代(dài)RNN成为(wéi)NLP中主(zhǔ)流(liú)模(mó)型的趋势(shì),现在更是谷歌(gē)云(yún)TPU推(tuī)荐的参考模型,包(bāo)括谷歌给自己TPU打广告的Bert就是Transformer模型。总的来说,在(zài)NLP任务上其性能比前(qián)两(liǎng)个(gè)神经网络的效果要好。
这彻底(dǐ)颠覆了过去的理念(niàn),没用到(dào) CNN 和 RNN,用更少的计算(suàn)资源,取得了比过去的(de)结构更好的结果。
Transformer引入有以下几个特点:提出用注意力机制来直接学习源语言内部关系和(hé)目标语言内部关系,1.抛弃之前(qián)用(yòng) RNN 来(lái)学习;2.对存(cún)在多种不同关系的(de)假设,而提出多头 (Multi-head) 注意力机制,有(yǒu)点类似于 CNN 中多通道的概念;3..对词语的位置,用了不(bú)同频率的 sin 和 cos 函数(shù)进行编码。
机器(qì)翻译任重(chóng)而道远
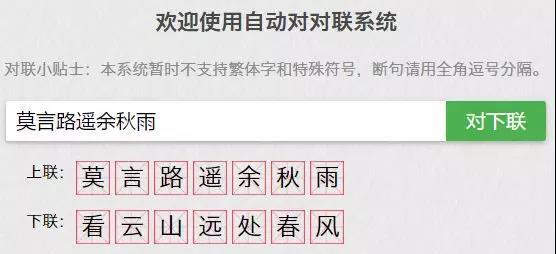
从对联(lián)的角(jiǎo)度来看,当前的(de)机器(qì)翻译还有很大的改进方向,例如前段(duàn)时间有句很火的上联“莫言路遥余秋雨(yǔ)”,我们用微软对联系统输入之后,就没有(yǒu)答案。出现这种问题的原因在于算法(fǎ)和数据集。

然而我们把这个上(shàng)联(lián)输入王(wáng)斌版的对(duì)联系统(tǒng),就会得(dé)到(dào)“看云山远(yuǎn)处春风”的下联。虽说给出(chū)了下(xià)联,但是意境和上(shàng)联相比却相差(chà)甚远:“莫言路遥余秋雨”的字面意思是近现代三位文(wén)人,意境是“不必言道路漫长空余寂寥秋雨”,AI给出的下联不(bú)仅在意境上无法呼应(yīng),字面意思也对(duì)应不上。
管(guǎn)中窥豹,仅此(cǐ)一例便能(néng)看出当前的机器翻译存在一些(xiē)问题,正如AI科技评(píng)论从百度处获(huò)悉(xī):“当前主要都是(shì)采用端到端序列(liè)生成的(de)模型来(lái)自动写(xiě)对(duì)联和写诗,对于一(yī)般用户(hù)来说生(shēng)成的春联(lián)或者诗(shī)歌读起(qǐ)来也能朗朗上口,感觉也(yě)不(bú)错。
从专业角(jiǎo)度来说其实还(hái)有(yǒu)很大(dà)的(de)改进空间,例如现有的模型都是基于语料学习生成的,而采集的春(chūn)联(lián)库通常(cháng)包含的词汇是有限的,生成的(de)春联(lián)有一定(dìng)的同质(zhì)性,内容(róng)新意上有待继续提升。其次是机(jī)器有时候会生(shēng)成一些不符(fú)合常理的内容(róng),对生(shēng)成内(nèi)容的理解也值得继续深挖(wā)。”
宏观到整个机器翻(fān)译层面,不同语言之间的机器(qì)翻译还(hái)存有很多技术难点亟待攻克,比如语(yǔ)序混乱、词义不准确等。
当前的(de)算法和算(suàn)力的发展确实能够解决一些特定的困难,但是机器翻译的研究应在以下三个方面有所突破:大语境,而(ér)不再是孤立句子地处理(lǐ);基于理解而不再(zài)是停留在句法分析(xī)的(de)层面;高度专业(yè)化和专门化(huà)。










络警(jǐng)察")


